Maarten Bezemer
2013-10-07 08:53:35 UTC
Hello,
I have a problem with pdflatex asked about at
http://tex.stackexchange.com/questions/136574/merging-duplicate-embedded-fonts
In the end I got suggested to further ask over here.
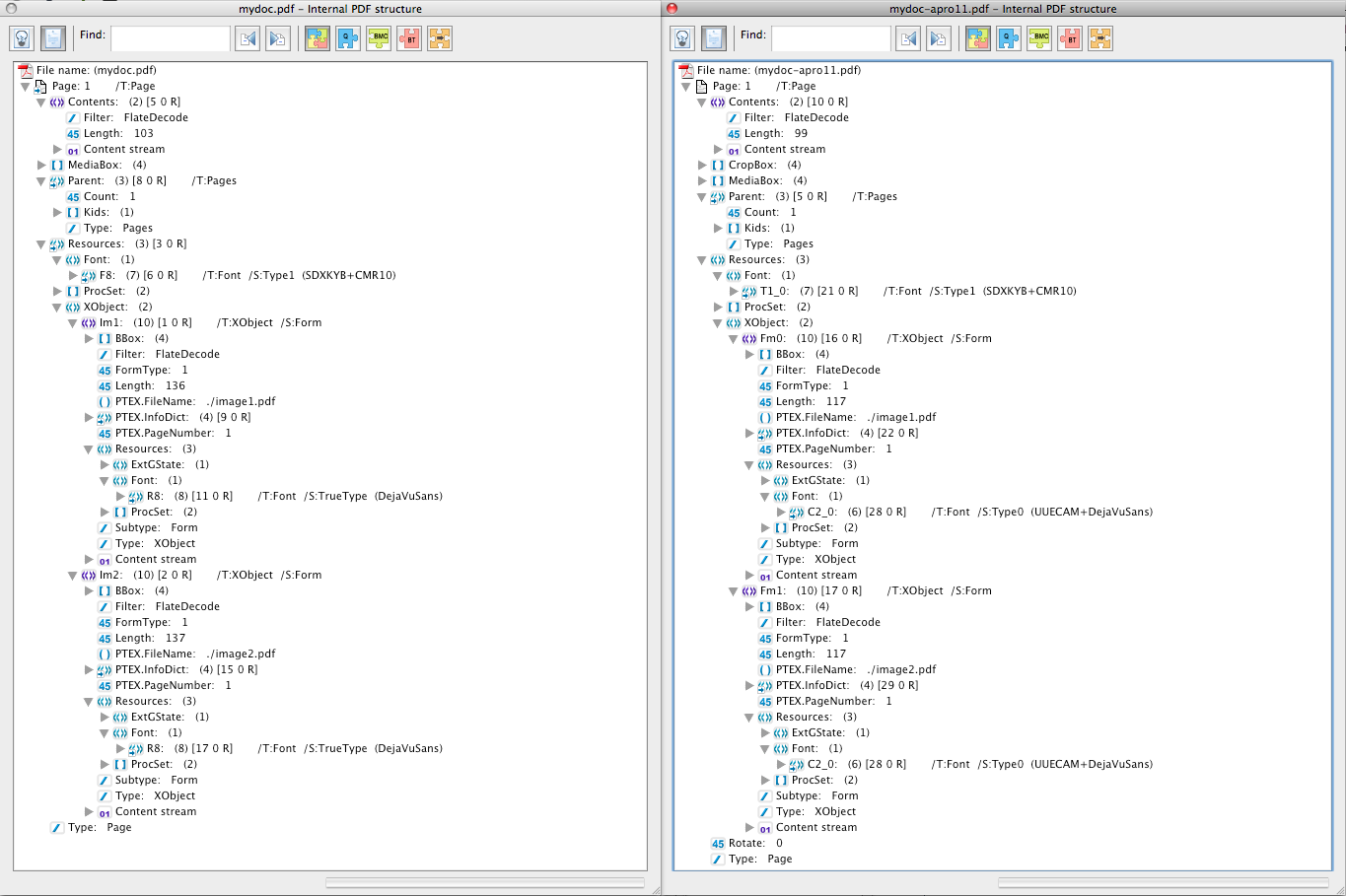
I have a LaTeX project that contains 2 PDF images. Both have a text with the
same font that is fully embedded (not subset, to keep things simple).
The PDF that is created from the LaTeX sources does contain the font twice,
once for each included image. I suppose that pdflatex should keep only one
copy, especially since both fonts are fully embedded so it is easy to
determine they are duplicate.
My LaTeX file is as follows:
\documentclass{article}
\usepackage{graphicx}
\begin{document}
\includegraphics{image1}
\includegraphics{image2}
\end{document}
pdffonts shows:
$ pdffonts mydoc.pdf
name type encoding emb
sub uni object ID
------------------------------------ ----------------- ---------------- ---
--- --- ---------
SDXKYB+CMR10 Type 1 Builtin yes
yes no 6 0
DejaVuSans TrueType WinAnsi yes no
yes 11 0
DejaVuSans TrueType WinAnsi yes no
yes 17 0
In my original document I have lots of images containing texts, resulting in
lots of duplicate fonts. Obviously, I normally use subsets reducing the size
of the final document. But I am (also) not able to merge the duplicate
subsets... So I thought to use fully embedded fonts, but those do also not
properly merge...
Am I doing something wrong resulting in the duplicate fonts? Or did I
encounter a bug in pdf(la)tex?
The resulting PDF file is set online [1], as well all the source files [2]
Best regards,
Maarten
[1]: https://dl.dropboxusercontent.com/u/9671810/mydoc.pdf
[2]: https://dl.dropboxusercontent.com/u/9671810/mydoc.zip
I have a problem with pdflatex asked about at
http://tex.stackexchange.com/questions/136574/merging-duplicate-embedded-fonts
In the end I got suggested to further ask over here.
I have a LaTeX project that contains 2 PDF images. Both have a text with the
same font that is fully embedded (not subset, to keep things simple).
The PDF that is created from the LaTeX sources does contain the font twice,
once for each included image. I suppose that pdflatex should keep only one
copy, especially since both fonts are fully embedded so it is easy to
determine they are duplicate.
My LaTeX file is as follows:
\documentclass{article}
\usepackage{graphicx}
\begin{document}
\includegraphics{image1}
\includegraphics{image2}
\end{document}
pdffonts shows:
$ pdffonts mydoc.pdf
name type encoding emb
sub uni object ID
------------------------------------ ----------------- ---------------- ---
--- --- ---------
SDXKYB+CMR10 Type 1 Builtin yes
yes no 6 0
DejaVuSans TrueType WinAnsi yes no
yes 11 0
DejaVuSans TrueType WinAnsi yes no
yes 17 0
In my original document I have lots of images containing texts, resulting in
lots of duplicate fonts. Obviously, I normally use subsets reducing the size
of the final document. But I am (also) not able to merge the duplicate
subsets... So I thought to use fully embedded fonts, but those do also not
properly merge...
Am I doing something wrong resulting in the duplicate fonts? Or did I
encounter a bug in pdf(la)tex?
The resulting PDF file is set online [1], as well all the source files [2]
Best regards,
Maarten
[1]: https://dl.dropboxusercontent.com/u/9671810/mydoc.pdf
[2]: https://dl.dropboxusercontent.com/u/9671810/mydoc.zip